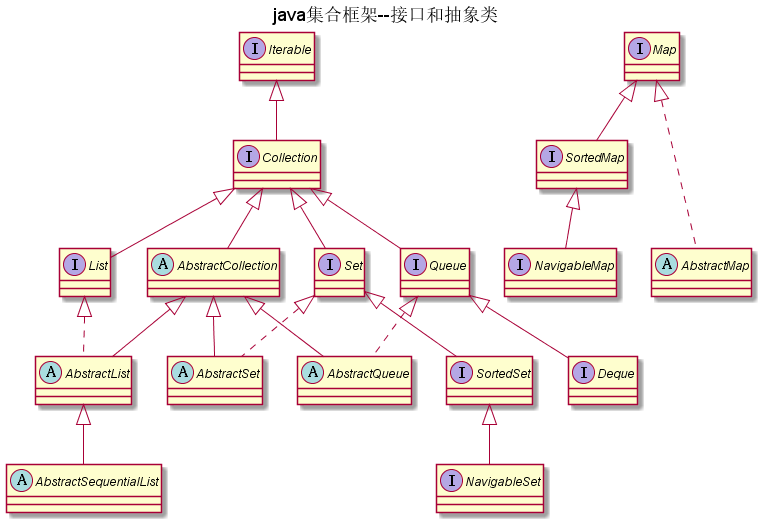
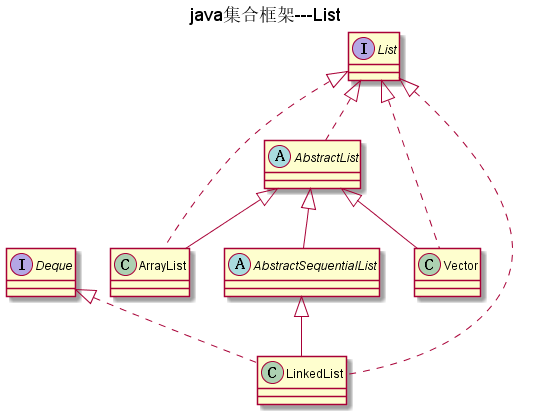
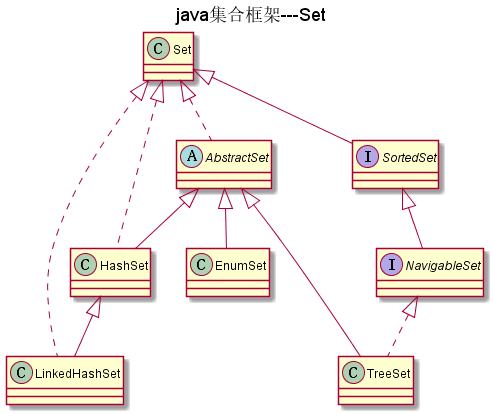
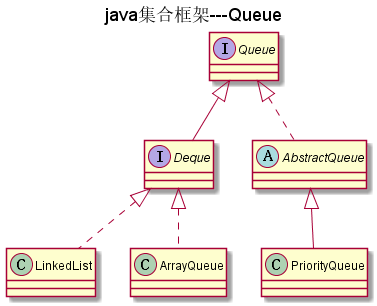
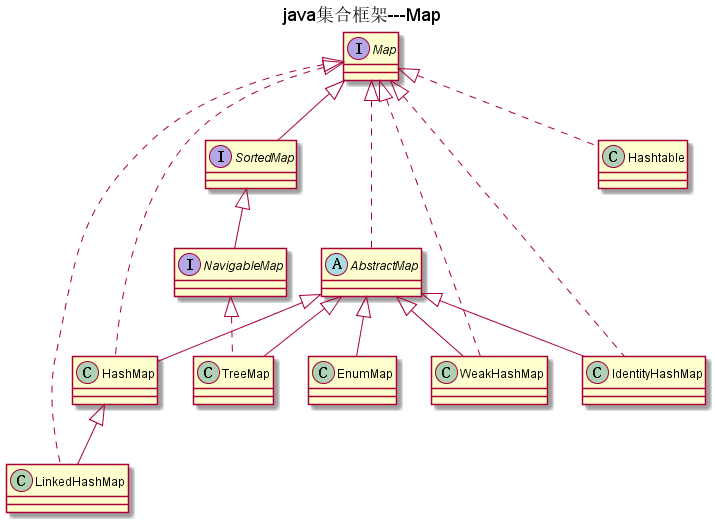
如图:
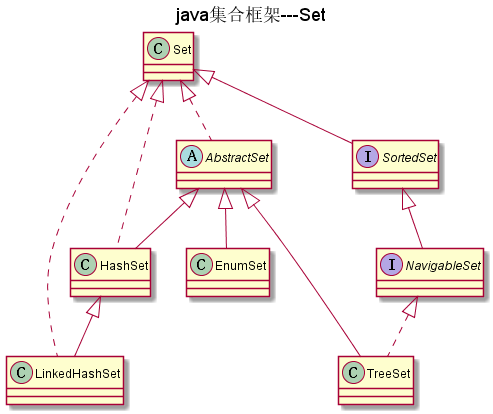
Set
不包含重复元素的集合(通过equals来判断),Set中只能包含一个null.当Set中存入
可变元素时,要特别注意,因为我们可能改变可变元素的值,从而影响对象相等的变更。
SortedSet
SortedSet接口定义了对元素进行自然排序的方法,实现它的类用对内部元素进行排序(这里的自然排序指的是升序排序)。
NavigableSet
NavigableSet扩展了 SortedSet,具有了为给定搜索目标报告最接近匹配项的导航方法。
方法 lower、floor、ceiling 和 higher 分别返回小于、小于等于、大于等于、大于给定
元素的元素,如果不存在这样的元素,则返回 null
AbstractSet
AbstractSet实现Set,是一个抽象类。AbstractSet只实现了equals(Object o),hashCode(),removeAll(Collection<?> c)
方法。
EnumSet
EnumSet 是一个专为枚举设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet
时显式或隐式地指定。
HashSet
HashSet依赖哈希表,它不保证集合中元素的顺序,即不能保证迭代的顺序与插入的顺序一致。HashSet允许null.
LinkedHashSet
LinkedHashSet继承HashSet,它与HashSet的区别是LinkedHashSet按照元素插入的顺序进行迭代,即迭代输出的顺序与插入的顺序保持一致
TreeSet
TreeSet 类同时实现了 Set 接口和 NavigableSet 接口。TreeSet是通过二叉树来实现的。