类,超类和子类
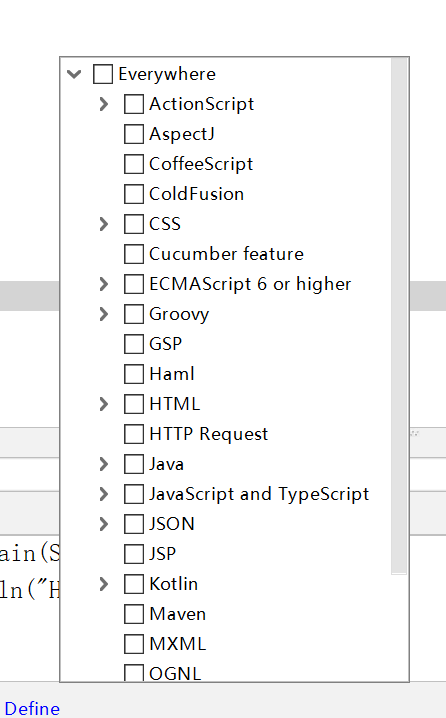
判断继承关系
如果类和另一个类之间存在is-a(什么是什么)关系,比如狗是动物,金鱼是鱼等。那么就可以使用继承
定义子类
关键字extends表示正在构造的子类继承(或派生)于一个以存在的类。这个以存在的类叫做超类(常用),基类或父类;新类
称为子类(常用),派生类和孩子类。例如:
格式:
1 | class 父类 { |
示例:
1 | public class Animal { |
从示例可以看到尽管Dog类没有显式地定义setName()和getName()等方法,但是属于Animal的类
却可以使用它们,这是因为Dog自动继承了超类Animal中这些方法(只能继承被public和protect修饰的字段)。
子类具有父类当中的属性和方法,子类就不会存在重复的代码,维护性也提高,代码也更加简洁,提高代码的复用性(复用性主要是可以多次使用,
不用再多次写同样的代码)
注意:Java只支持单继承
覆盖方法
如果我们对父类中已有的方法不满意,就可以自己覆盖父类的方法。例如:
1 | public class Dog extends Animal { |
注意:在覆盖一个方法时,子类的方法不能低于超类的可见性。特别是,如果超类的方法为public,子类方法
一定要声明为public;覆盖时的返回值可以从父类型改为对应的子类型。
super
super是一个指示编译器调用超类方法的特殊关键字。示例:
1 | public class Dog extends Animal { |
子类构造器
1 | package five; |
由于Dog类的构造器不能访问Animal的私有域,所有必须利用Animal类的构造器对这部分私有域进行
初始化,我们可以通过super关键字实现对超类构造器的调用。使用super调用构造器的语句必须是子类
构造器的第一条语句
如果子类构造器没有显式地调用超类的构造器,则自动地调用超类默认的(不带参数的)构造器。如果超类没有默认
的构造器,并且在子类的构造器中又没有显式地调用超类的其他构造器,则Java编译器报告错误。
多态
转载菜鸟教程
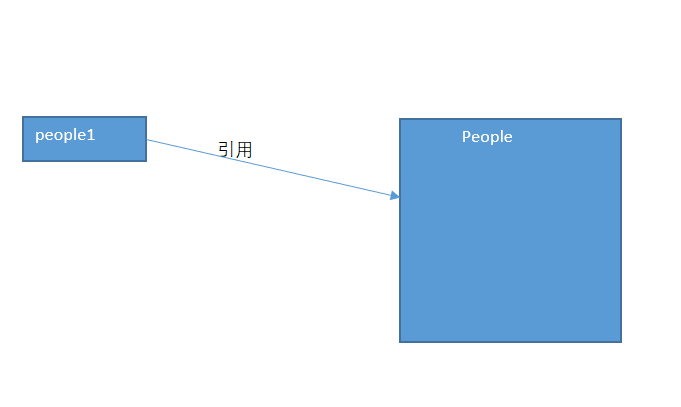
在Java中,对象变量是多态的,一个Animal变量既可以引用一个Dog类对象,也可以引用一个Animal类的任何
一个子类的对象。
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误;如果有,再去调用子类的同名方法。
多态的好处:可以使程序有良好的扩展,并可以对所有类的对象进行通用处理。
以下是一个多态实例的演示,详细说明请看注释:
1 | public class Test { |
注意:不能将一个超类的引用赋给子类变量;但是在Java中,子类数组的引用可以转为超类数组的引用,而不需要采用强制类型转换
继承中方法的调用
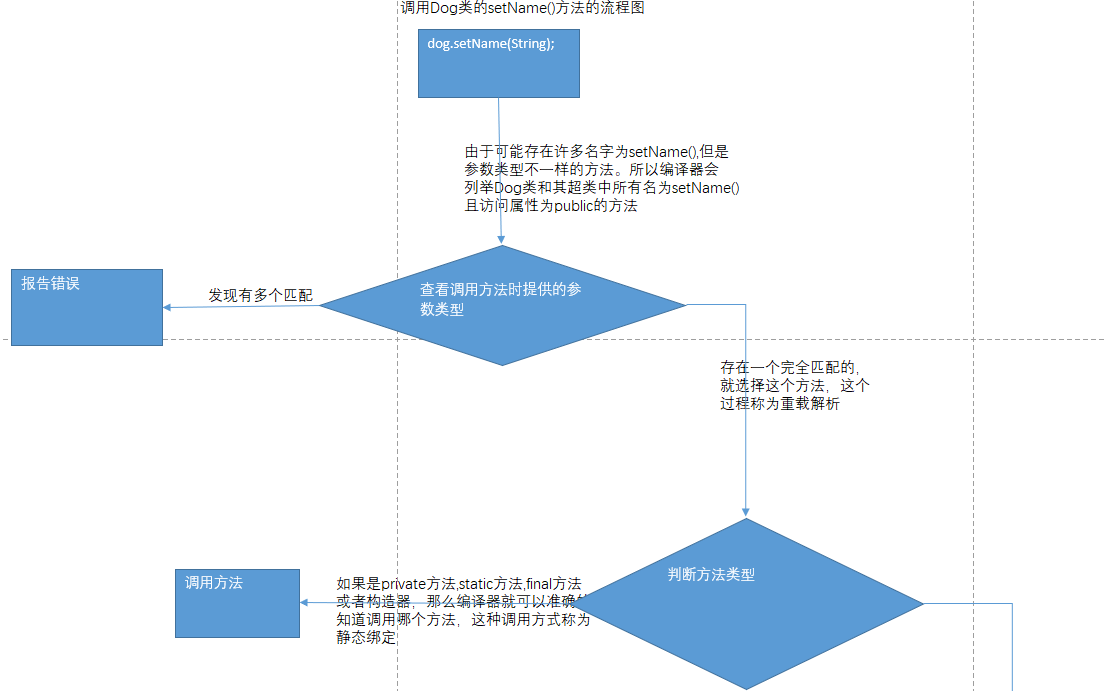
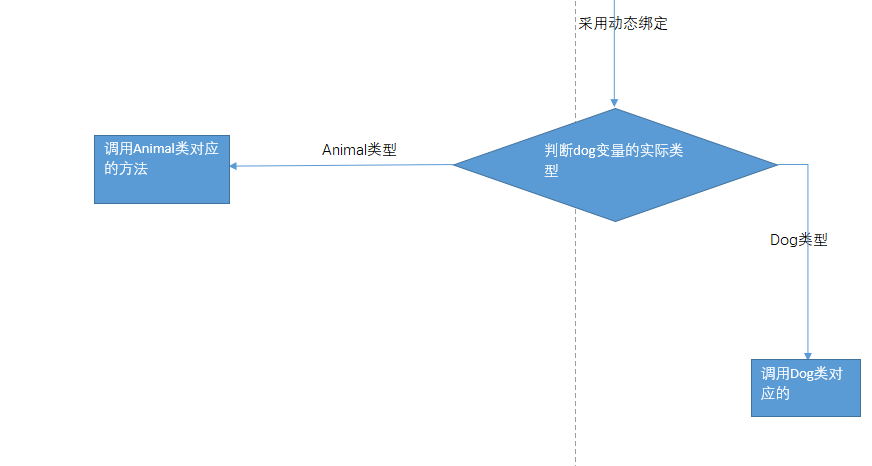
注意:上面流程图中判断方法类型中判断private方法是在dog.setName()方法中可能调用了private方法,调用这个private方法时要重新走这个流程所以要判断。
每次调用方法都要进行搜索,时间开销大。因此,虚拟机预先为每一个类创建了一个方法表,其中列出了所有方法的签名和实际调用的方法。这样一来
,在真正调用这个方法时,虚拟机只查这个表就行。
final类和方法
为类加上final,该类就无法被继承;为方法加上final,该方法就无法被覆写
instanceof
instanceof是用来在运行时指出对象是否是特定类的一个实例,instanceof通过返回一个布尔值来指出,这个对象是否是这个特定类或者是它的子类的一个实例
1 | if(dog instanceof Animal){//如果 dog = null,会返回false |
抽象类
转载菜鸟教程
在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。
抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。
由于抽象类不能实例化对象,所以抽象类必须被继承,才能被使用。也是因为这个原因,通常在设计阶段决定要不要设计抽象类。
父类包含了子类集合的常见的方法,但是由于父类本身是抽象的,所以不能使用这些方法。
在Java中抽象类表示的是一种继承关系,一个类只能继承一个抽象类,而一个类却可以实现多个接口。
抽象类的定义
在Java语言中使用abstract class来定义抽象类。如下实例:
1 | /* 文件名 : Employee.java */ |
注意到该 Employee 类没有什么不同,尽管该类是抽象类,但是它仍然有 3 个成员变量,7 个成员方法和 1 个构造方法。 现在如果你尝试如下的例子:
1 | /* 文件名 : AbstractDemo.java */ |
当你尝试编译AbstractDemo类时,会产生如下错误:
1 | Employee.java:46: Employee is abstract; cannot be instantiated |
继承抽象类
我们能通过一般的方法继承Employee类:
1 | /* 文件名 : Salary.java */ |
尽管我们不能实例化一个 Employee 类的对象,但是如果我们实例化一个 Salary 类对象,该对象将从 Employee 类继承 7 个成员方法,且通过该方法可以设置或获取三个成员变量。
1 | /* 文件名 : AbstractDemo.java */ |
以上程序编译运行结果如下:
1 | Constructing an Employee |
抽象方法
如果你想设计这样一个类,该类包含一个特别的成员方法,该方法的具体实现由它的子类确定,那么你可以在父类中声明该方法为抽象方法。
Abstract 关键字同样可以用来声明抽象方法,抽象方法只包含一个方法名,而没有方法体。
抽象方法没有定义,方法名后面直接跟一个分号,而不是花括号。
1 | public abstract class Employee |
声明抽象方法会造成以下两个结果:
如果一个类包含抽象方法,那么该类必须是抽象类。
任何子类必须重写父类的抽象方法,或者声明自身为抽象类。
继承抽象方法的子类必须重写该方法。否则,该子类也必须声明为抽象类。最终,必须有子类实现该抽象方法,否则,从最初的父类到最终的子类都不能用来实例化对象。
如果Salary类继承了Employee类,那么它必须实现computePay()方法:
1 | /* 文件名 : Salary.java */ |
抽象类总结规定
- 抽象类不能被实例化(初学者很容易犯的错),如果被实例化,就会报错,编译无法通过。只有抽象类的非抽象子类可以创建对象。
- 抽象类中不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
- 抽象类中的抽象方法只是声明,不包含方法体,就是不给出方法的具体实现也就是方法的具体功能。
- 构造方法,类方法(用 static 修饰的方法)不能声明为抽象方法。
- 抽象类的子类必须给出抽象类中的抽象方法的具体实现,除非该子类也是抽象类
protected
protected修饰的方法和属性对本包和所有子类可见。在实际应用中,要谨慎使用protected属性。
Object
Object类是Java中所有类(不包括基本数据类型)的超类,在Java中每个类都是由它扩展而来的。如果没有明确指出超类,Object就被
认为是这个类的超类,所以不需要这样显式声明
1 | public Animal extends Object{ |
所有的数组类型,不管是对象数组还是基本类型的数组都扩展Object类